Sparklyr: entorno para Big Data con R
16 Julio, 2019
¿Qué es sparklyr?
Expone la API de Spark (en Scala) desde R.
Spark permite acceder al ecosistema Hadoop.
Simplemente, sintaxis dplyr!.
Creado por Rstudio en 2016.



¿Qué es ‘Big Data’?
Lectura y escritura de datos a gran escala, por:
- Volumen (Gb, Tb).
- Variedad / Complejidad.
- Velocidad (streaming).

¿Qué es ‘Big Data’?
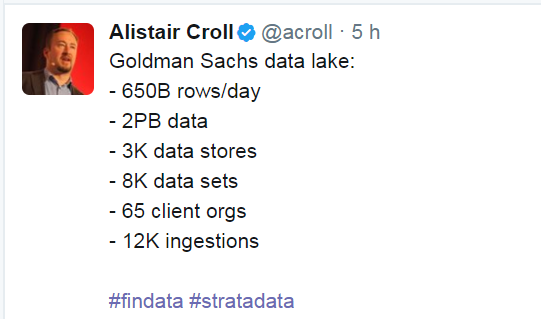
Big Data y Sparklyr

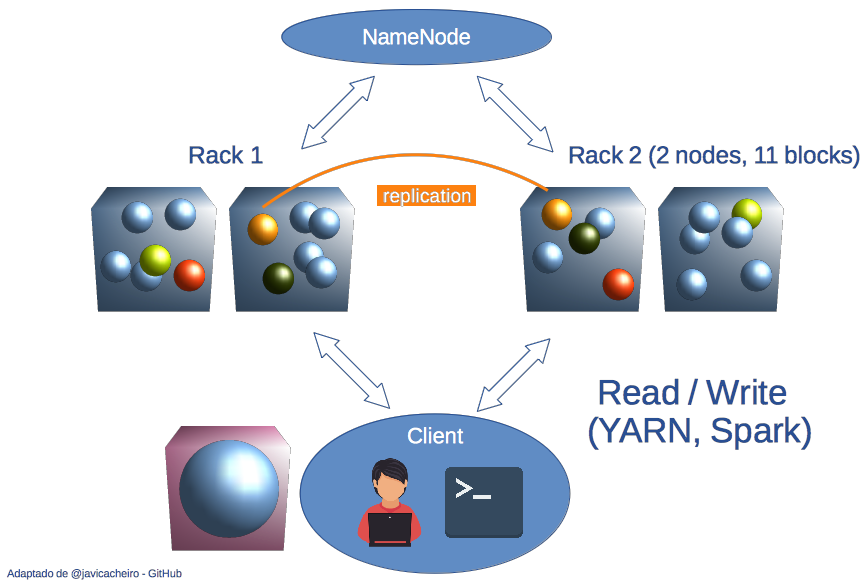
RDD’s
Resilient Distributed Database.
Formato de archivo básico para HDFS.
Compuesto de bloques, duplicados en varios nodos.
Se recuperan en caso de pérdida de algún nodo.
Base de los dataframes utilizados por sparklyr.
Cómo funciona Spark?

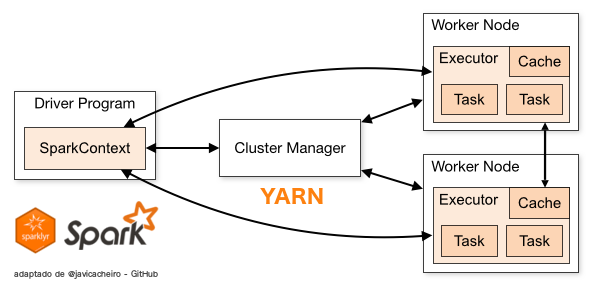
# Spark context: local (for 'low memory' tasks only!)
sc <- spark_connect(master = "local",
spark_home = "/usr/hdp/2.4.2.0-258/spark")
# Spark context: yarn (for loading bigger datasets)
sc <- spark_connect(master = "yarn-client",
spark_home = "/usr/hdp/2.4.2.0-258/spark")Ejemplos
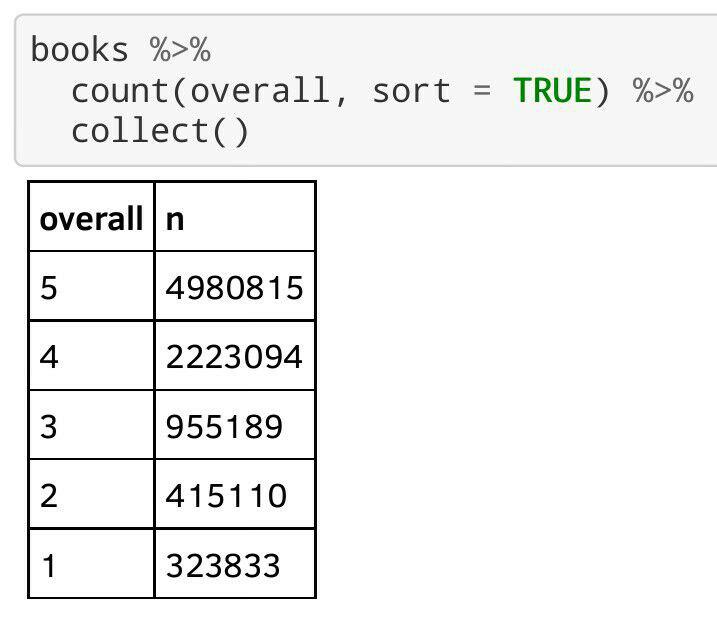
Opiniones de libros en Amazon
Modelos de regresión y ‘machine-learning’
Stickers!
![]()