R/Shiny for clinical trials: simple randomization tables
One of the things I most like from R + Shiny is that it enables me to serve the power and flexibility of R in small “chunks” to cover different needs, allowing people not used to R to benefit from it. However, what I like most is that’s really fun and easy to program those utilities for a person without any specific programming background.
Here’s a small hack done in R/Shiny: it covered an urgent need for a study involving patient randomisation to two branches of treatment, in what is commonly known as a clinical trial. This task posed some challenges:
First, this trial was not financed in any way (at least initially). It was a small, independent study comparing two approved techniques for chronic pain, so the sponsor had to avoid expensive software or services.
Another reason for software customization is that treatment groups were partially ‘blind’: for people who assessed effectiveness and… also for statistical analysis (treatment administration was open-label). This means that the person in charge of data analysis must know which group is assigned to a patient, but doesn’t know what treatment is assigned to either group.
To tackle the points above, my app should have two main features:
The sponsor (here, a medical doctor) must be able to effectively control study blindness and also provide emergency blind disclosure. This control should extend to data analysis to minimize bias favoring either treatment.
R has tools to create random samples, but the MD in charge of the study sponsoring doesn’t know how to use R. We needed a friendly interface for random table creation.
Here’s how I got it to work:
The very core of this Shiny app is a combination between the set.seed and sample R functions. The PIN number (the set.seed argument) works like a secret passcode that links to a given random table. E.g., every time I enter ‘5432’, the random tables will look the same. This protects from accidental blindness disclosure, as nobody can find the correct random table without the proper PIN, even if they can access the app’s source code.
The tables are created column by column, ordered at first. Then we proceed to randomize (via the sample function) both the treatment column (in the random table) and the Group column (in the PIN table).
Once the tables are created they can be downloaded as .CSV files, printed, signed and dated to document the randomization procedure. The app’s open source code and the PIN number will provide reproducibility to the procedure for many years.
Unfortunately I wasn’t able to insert iframes to embed the app, so I posted a screenshot:
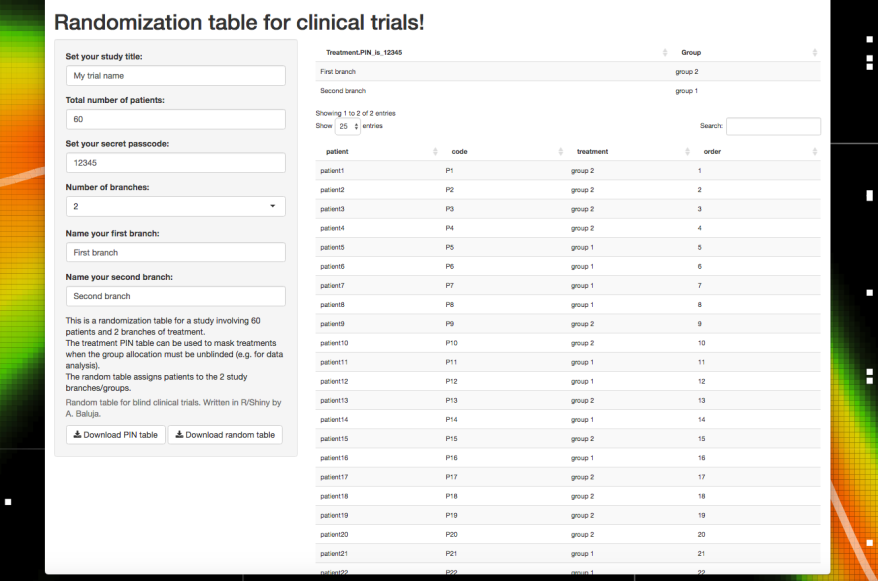
The app is far from perfect, but it covers the basic needs for the trial. You can test it here:
And the GitHub repo is available here. Feel free to use/ adapt/ fork it to your needs!
Also, you can cite it if it’s been useful for your study methods!
